Ever wondered what really happens inside a PyTorch training loop? In this walkthrough, we break down every step — forward pass, loss, gradients, and weight updates — using a tiny neural network and simple whole-number examples. By the end, you’ll understand not just how the code runs, but how the math drives learning.
The Code
Let’s create a small model with a single linear layer of 1 neuron, with 2 input features and one output.
import torch
import torch.nn as nn
import torch.optim as optim
# data
x = torch.tensor([1, 2], dtype=float) # input with two features
y = torch.tensor([8], dtype=float) # output
model = nn.Linear(2, 1) # 2 input — 1 output
# manually set weights and bias for easy calculation
model.weight.data = torch.tensor([1, 1], dtype=float)
model.bias.data = torch.tensor([0], dtype=float)
# loss and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
pred = model(x)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()This is how the neural network looks visually.
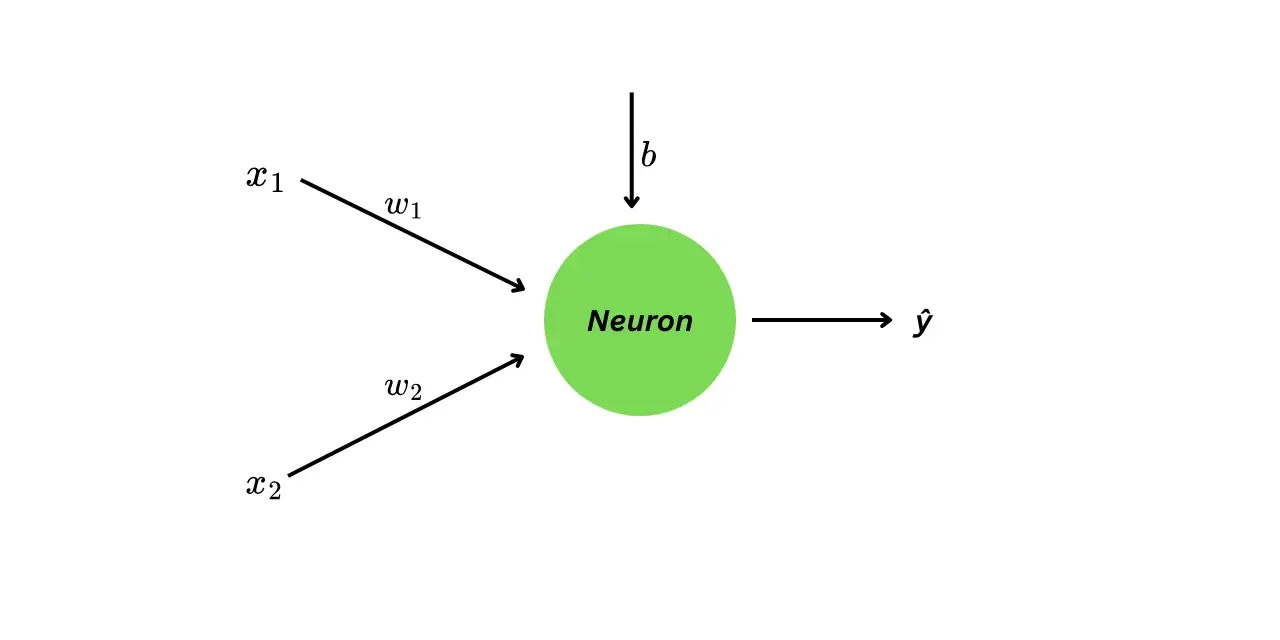
The neural network has three parameters:
- weight (for feature )
- weight (for feature )
- bias
We initialize them manually for easier calculation as -
Step 1 — Forward pass (Prediction)
For the first training example:
The prediction is computed using -
Substituting the values of all variables we will get:
The model predicted 3, but the target is 8, so it’s clearly off.
Step 2 — Loss Computation
This step determines how wrong the model’s prediction is.
This is represented by function call like loss_fn(pred, y).
The first thing we measure is, the error — how far the prediction is from the true value:
Errors by themselves aren’t enough for training, because we’ll have many predictions over time and we need a single number that summarizes how good or bad the model is. That number is the loss.
In this example, we are using the Mean Squared Error (MSE) loss:
Plugging in the values, we get:
Since :
The model works to reduce this loss during training.
Step 3 — Gradients (Backpropagation)
We calculate gradients when we call loss.backward().
Up to this point the model has made a prediction and we’ve calculated how wrong it is using the loss function. Now the model needs to answer a very specific question:
If I adjust each parameter just a tiny bit, will the loss go up or down — and by how much?
That “how much” is the gradient.
If you know basic calculus, this is the rate of change.
Here we will use the partial derivatives () since the loss depends on multiple variables at the same time (, and ).
So we have to calculate:
These tell us how sensitive the loss is to each parameter.
Let’s look at the first term, since does not directly depend on the , we can use chain rule.
The Loss depends on error , which depends on prediction , which in turns depends on the weight . So by chain rule:
Let’s compute these terms one by one.
Derivative of w.r.t. -
Derivative of w.r.t -
(Here is constant)
Derivative of w.r.t -
Here everything is a constant except the parameter .
Final gradient for :
We follow the exact same pattern for and :
Plugging in numbers:
Each gradient tells us how the loss reacts to each parameter.
For example, for means:
If increases slightly, the loss will go down by about times that amount.
Step 4: Updating parameters
The parameters are updated when calling optimizer.step().
We have computed the loss and its gradients with respect to each parameters. Now the model actually adjusts its parameters to reduce the loss.
This follows the gradient descent update rule:
is the learning rate — how big a step we take in the opposite direction of the gradient.
We apply this formula to each parameter independently.
Update for
Update for
Update for
Here is the summary after updates -
| Parameter | Old value | Gradient | New value |
|---|---|---|---|
| 1.0 | –10 | 1.1 | |
| 1.0 | –20 | 1.2 | |
| 0.0 | –10 | 0.1 |
After applying gradient descent, the parameters shift slightly in the direction that reduces the loss.
I’ve also created a Jupyter Notebook with the code. Experiment with it and tweak the numbers — the more you play with the math, the faster the intuition sinks in.